

La alta disponibilidad (HA, del inglés High Availability) elimina los puntos únicos de fallo en sistemas TI para minimizar el impacto de una interrupción en sistemas, bases de datos y aplicaciones. Esto reduce el riesgo de dañar la productividad y perder ingresos. La redundancia y la detección automática de fallos son aspectos clave para la HA.
Alta disponibilidad y rendimiento operativo
La alta disponibilidad hace referencia a un nivel de rendimiento operativo acordado, superior al normal durante un determinado período de tiempo. En caso de fallo, las infraestructuras en alta disponibilidad garantizan un tiempo de inactividad mínimo.
Los servicios críticos en los centros de datos demandan alta disponibilidad para garantizar que los sistemas estén siempre disponibles.
El nivel de disponibilidad se establece a modo de porcentaje en el SLA (Service Level Agreement). Por ejemplo, el SLA de Stackscale garantiza disponibilidad de red del 99,95 % y disponibilidad del hardware del 99,90 %. Además, los centros de datos en los que alojamos nuestra infraestructura garantizan un 99,99 % de disponibilidad SLA.
Alta disponibilidad vs. tolerancia a fallos
Ambas técnicas sirven para proporcionar un alto nivel de tiempo de actividad. Sin embargo, cada una de ellas alcanza dicho objetivo de forma diferente:
- La alta disponibilidad se consigue uniendo un grupo de servidores. En caso de que falle el servidor principal, uno de los servidores de respaldo dentro del clúster lo detecta y reinicia el servicio. La monitorización del entorno es clave en la HA.
- La tolerancia a fallos se consigue replicando los sistemas de modo que el sistema en standby tome el relevo sin interrupciones cuando el sistema principal falle. Esto implica la redundancia completa del hardware.
Métricas de alta disponibilidad
Al igual que en la planificación del Disaster Recovery del negocio, las métricas RPO y RTO se usan para evaluar la alta disponibilidad.
- RTO u «Objetivo de tiempo de recuperación» define el tiempo máximo durante el cual es aceptable que un fallo afecte a la actividad normal. Las aplicaciones de misión crítica requieren un RTO muy bajo o incluso nulo (RTO=0) a ser posible.
- RPO u «Objetivo de punto de recuperación» define la cantidad máxima de datos que la empresa está dispuesta a perder durante un fallo.
Es importante encontrar el equilibrio adecuado entre tolerancia y presupuesto al elegir la solución de HA idónea para cada proyecto. Así que, al medir el tiempo de inactividad aceptable en un negocio, hay varios aspectos a tener en cuenta:
- Tiempo de inactividad por mantenimiento planificado o sin planificar.
- Tiempo de inactividad por fallos de software o hardware.
- Tiempo de actividad a nivel de la base de datos y aplicaciones.
- El impacto del tiempo de inactividad en la experiencia de usuario.
- Pérdida de datos tolerable.
- Sistemas y aplicaciones críticos para el negocio.
Sistemas y aplicaciones de misión crítica
Las aplicaciones de misión crítica requiere objetivos de RPO y RTO lo más bajos posible. Algunos de los sistemas críticos para el negocio son: CRMs, software de comercio electrónico, aplicaciones de gestión de la cadena de suministro, sistemas de inteligencia de negocio, bases de datos, etc.
Descubre este caso de éxito en el que se aborda la importancia de la alta disponibilidad en sitios eCommerce para soportar grandes picos de tráfico y el crecimiento de la demanda.
Clústeres de alta disponibilidad
Los clústeres de HA son grupos de servidores que trabajan en conjunto para soportar aplicaciones de misión crítica que quieren un rendimiento máximo y un tiempo de inactividad mínimo. Se caracterizan por:
- Conmutación automática a un sistema redundante, lo cual elimina los puntos únicos de fallo.
- Detección automática de fallos a nivel de aplicación.
- Garantía de ninguna pérdida de datos.
- Conmutación manual durante tareas de mantenimiento planificadas.
Los clústeres de alta disponibilidad garantizan un rendimiento óptimo durante un fallo potencial. También se conocen como «failover clusters» en inglés y se pueden configurar de diversas formas, por ejemplo:
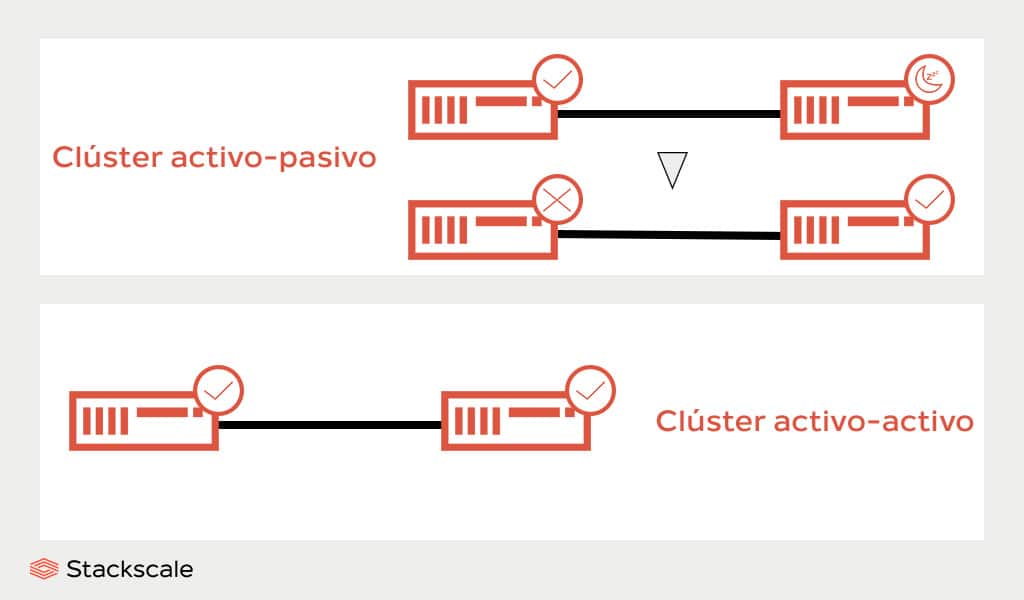
- Clústeres activo-pasivo. En un clúster de dos nodos, uno de los nodos está activo y el otro permanece en standby. Los nodos pasivos están listos para reemplazar al nodo activo en caso de fallo.
- Clústeres activo-activo. En un clúster de dos nodos, ambos nodos están activos simultáneamente y cualquiera de ellos puede aceptar peticiones de lectura y escritura. En caso de que uno de los nodos falle, todas las peticiones pasarían automáticamente a través del otro nodo activo.
Arquitectura en alta disponibilidad
Una arquitectura en alta disponibilidad tiene como objetivo eliminar los puntos únicos de fallo y optimizar el rendimiento durante los períodos de alta demanda. Algunos aspectos importantes de las infraestructuras en HA son:
- Balanceo de carga para transmitir datos de modo más eficiente y evitar la sobrecarga del servidor.
- Redundancia geográfica.
- Estrategia de backup y disaster recovery.
- Escalabilidad.
- Conmutación automática.
Ejemplo de arquitectura en HA
La alta disponibilidad se puede conseguir dentro del mismo centro de datos, a nivel del nodo, y también contando con dos centros de datos geográficamente distantes. El siguiente ejemplo de arquitectura en HA incluye dos centros de datos para mejorar la disponibilidad. Los nodos y todos los elementos de red están redundados tanto en el datacenter activo como en el secundario. Por lo tanto, en caso de contingencia grave en el CPD activo, el nodo o nodos en el segundo centro de datos pueden hacerse cargo del servicio. No obstante, para asegurar un RTO=0 en el servicio, los sistemas operativos, BBDD y aplicaciones también deben soportar este tipo de arquitectura y configurarse como tal.
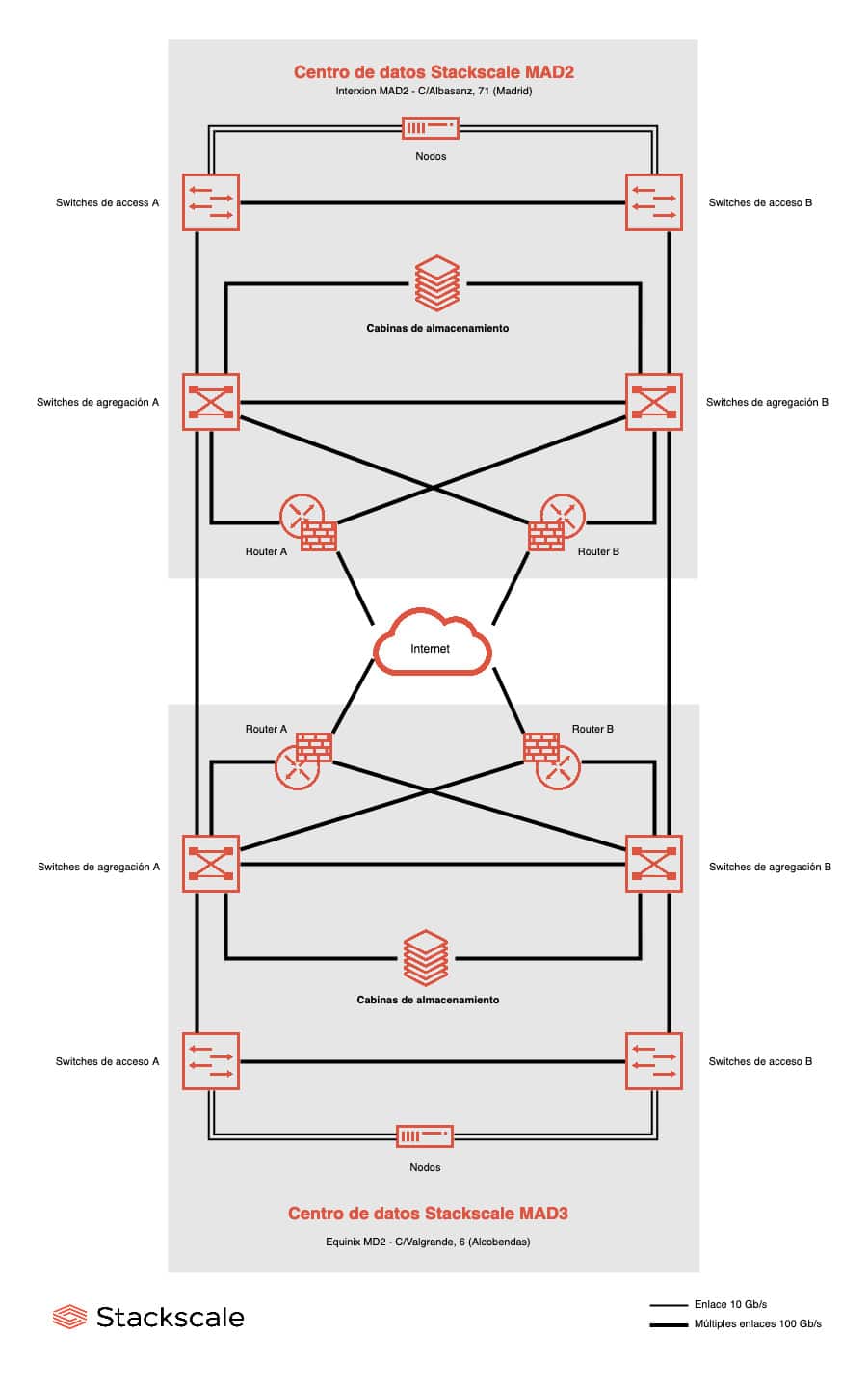
En Stackscale ofrecemos nodos de computación en alta disponibilidad por defecto, y redundancia a nivel de centro de datos opcionalmente. La plataforma de automatización y monitorización de Stackscale proporciona un nivel de protección bastante similar a VMware HA. Sin embargo, VMware HA necesita un nodo de reserva dentro del clúster del cliente, mientras que en Stackscale mantenemos un pool de nodos de reserva a disposición de todos nuestros clientes sin coste adicional, lo que permite el uso completo de los nodos de computación, al mismo tiempo que se conservan las capacidades de HA.
Por último, cabe mencionar que el hecho de disponer de una infraestructura en alta disponibilidad no exime a las empresas de contar con un plan de DR para maximizar la continuidad del negocio. Por un lado, la estrategia de HA permite restaurar el servicio durante fallos críticos menores en algunos componentes. Por otro lado, la estrategia de Disaster Recovery es necesaria para superar catástrofes e incidentes más graves que puedan afectar al centro de datos.



